

por Luís Flávio Fernandes - Julho/2017
A busca do mercado pelo elusivo
mago da era da informação
A segunda estória mais repetida pelos vendedores de ferramentas de tecnologia nos dias atuais é a da reeleição do presidente americano Barack Obama*. Consta que todas as pesquisas de opinião davam sua derrota como certa, mas, graças ao uso de tecnologia, sua campanha conseguiu atingir e movimentar o eleitorado do Partido Democrata. Isso não só trouxe a vitória nas urnas (bastante apertada, por sinal), mas modificou definitivamente a forma como se fazem campanhas políticas.
O que isso significa? Resumindo o “milagre” tecnológico dos Democratas, os coordenadores da campanha resolveram criar um time de tecnologia heterodoxo e adotar uma estratégia inovadora, voltada para a análise de dados. Começando com a unificação das inúmeras bases de dados de eleitores, e buscando um conhecimento profundo de seus perfis, eles conseguiram atacar dois pontos chaves de qualquer eleição: 1) que tipo de ações e eventos deveriam fazer para arrecadar fundos, e quais pessoas deveriam ser convidadas para cada um deles; e 2) qual forma de comunicação (e-mail, telefone, visita física) deveria ser usada para convencer cada eleitor a sair de casa e ir ao local de votação para depositar seu voto.
Parece simples? Posso garantir que não é. Na verdade, esse é um ótimo exemplo do que é o trabalho de um data scientist, o misterioso e raro cientista de dados. Em geral, depois que uma ideia inovadora vem à tona pela primeira vez, é muito fácil replicá-la, e ela se torna um proverbial “ovo de Colombo”. No caso desse “milagre eleitoral”, entretanto, cada novo “milagre” operado pelos cientistas de dados exige conhecimento profundo e muitos anos de prática em uma série de disciplinas complexas.

* A primeira estória mais repetida é esta:
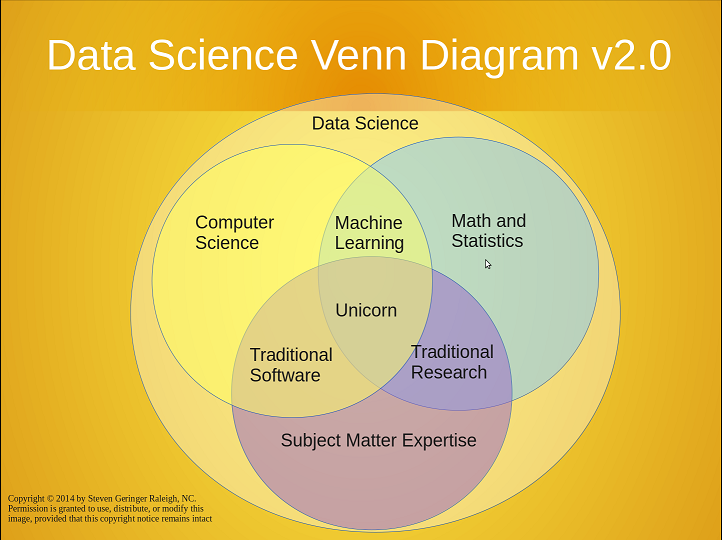
Mas quem é o cientista de dados? Que conhecimentos ele precisa ter para fazer seu trabalho? Esse tipo de profissional se tornou o grande “unicórnio” da área de tecnologia: se ele realmente existir, custará tão caro contratá-lo que é melhor esquecer o assunto. Mas a verdade é que o cientista de dados é tão real quanto os problemas que ajuda a resolver, e quando se deixam de lado os mitos, não há nada de mágico no seu trabalho.
Como encontrá-lo, então? E como saber se ele é realmente qualificado para liderar os projetos de data science de uma empresa? Embora essa pergunta seja importante, antes de analisar quem é o cientista de dados, vale a pena lembrar qual é a sua missão, ou seja, porque uma empresa precisa dessa figura tão difícil de encontrar.
A motivação básica por trás do conceito de data science é... um outro conceito complexo, mas não tão difícil de entender: data-driven decision-making – em tradução livre, tomada de decisão orientada por dados. Para profissionais do século XXI atuando em qualquer área de negócios, não é nenhum mistério: informação representa valor. Seja para orientar uma campanha de marketing, maximizando o impacto nas vendas, ou para identificar clientes insatisfeitos e tentar minimizar perdas de faturamento, tomar decisões com base em informações consistentes é sempre melhor para os negócios do que dar um tiro no escuro. Nesse contexto, podemos dizer, de forma bastante simplista, que o papel do cientista de dados é fornecer as melhores informações possíveis, para as áreas de negócio tomarem as melhores decisões possíveis. Voltaremos a esse ponto (e à eleição americana) um pouco mais à frente.
Antes disso, podemos listar cinco disciplinas básicas que fazem parte do dia a dia de um cientista de dados (embora não necessariamente sejam ou constituam data science isoladamente), bem como o tipo de conhecimento que cada uma delas engloba:

Projetos de data science naturalmente envolvem processamento de dados, e por isso, o trabalho de um cientista de dados será bastante facilitado se ele dominar as ferramentas dessa área. Conhecimentos de lógica e algoritmos básicos são certamente um pré-requisito. Além disso, linguagens de programação são essenciais para qualquer profissional cuja atividade envolva simulação de modelos e análise de dados. Mesmo quem não tiver experiência com uma linguagem mais avançada, como C ou C++, deve saber se virar com linguagens mais amigáveis e práticas, como Python. A mais indicada para análises complexas, e por isso mesmo preferida pelos cientistas de dados, é o R. Nesse quesito em particular, quanto mais linguagens, melhor. Conceitos avançados como machine learning e inteligência artificial também são importantes.
Entender pelo menos um pouco de arquitetura de sistemas também é desejável, já que obter, consolidar e analisar dados pode envolver interações entre múltiplos sistemas e tipos de dados diversos. Servidores de Bancos de Dados, Aplicação, Web, redes, interfaces de usuários, entre outros componentes, têm impacto na forma como as informações são fornecidas, formatadas, trafegam entre as diversas camadas de um sistema, são armazenadas e posteriormente requisitadas, recuperadas e analisadas. Mesmo que seja possível recorrer a especialistas em cada uma das peças desse quebra-cabeças, conhecê-las facilita a interação com esses profissionais, e também a antecipação das limitações que podem surgir no decorrer de um projeto.
Devemos ressaltar que conhecer ferramentas de tecnologia não transforma ninguém em um cientista de dados, mas saber escolher e usar as ferramentas corretas, no atual estágio do mercado, é fundamental para um professional dessa área.

É muito difícil pensar em data science sem o uso de estatística e métodos numéricos avançados. Conceitos como classificação, estimativa de probabilidades, agrupamento por similaridades, clusterização, regressão, redução de dados, modelagem causal, modelagem preditiva entre muitos outros, são fundamentais para a extração de informações úteis a partir de dados brutos - que é o ganha pão de um cientista de dados. Um curso superior em matemática, estatística, ou mesmo engenharia, pode ajudar bastante nesse ponto, mas a experiência adquirida com a experimentação em projetos diversos é o complemento indispensável a esse tipo de conhecimento. Escolher o modelo matemático mais adequado para resolver cada problema específico vai muito além dos conceitos teóricos - e mesmo problemas similares podem exigir soluções distintas, dependendo dos dados disponíveis para análise. Além disso, é preciso saber como testar e validar os modelos escolhidos e evitar armadilhas como o overfitting (modelos "viciados" por serem criados com base apenas em dados de teste).
Vale lembrar que nem todo matemático é um cientista de dados, mas o conhecimento e a prática em matemática avançada são indispensáveis nessa área.

Esta disciplina é um complemento às ferramentas de tecnologia mencionadas anteriormente. Outras linguagens e processos, como SQL e ETL, sistemas relacionais, analíticos e multi-dimensionais, se somam aos recursos que devem facilitar a vida de um cientista de dados. Com a chegada das tecnologias de Big Data, um novo arsenal se apresenta para aumentar a complexidade dos projetos. Um bom profissional de data science deveria saber quando é necessário utilizar um banco de dados relacional ou NoSQL, um data warehouse com processamento massivamente paralelo, ou mesmo todos esses recursos em conjunto.
Saber como adequar a modelagem dos dados a cada tipo de uso, e que tipo de ferramentas usar para armazenar e recuperar informações da forma mais eficiente, é o trabalho de administradores de bancos de dados (DBAs). Um cientista de dados não precisa necessariamente ter um conhecimento avançado nessa área, mas é claro que isso ajuda. A correta modelagem de dados é mais importante do que os softwares utilizados – bancos de dados, data warehouses, plataformas de business intelligence, são apenas ferramentas: necessárias, mas não suficientes para atingir os objetivos de um projeto.

Um projeto de data science tem os mesmos requisitos básicos de qualquer outro tipo de projeto: trabalho em equipe, gerenciamento de expectativas, e apresentação de resultados são essenciais. Um cientista de dados deve se preocupar inicialmente em entender e alinhar as expectativas, para que o projeto tenha sucesso segundo o ponto de vista de quem o demandou. E é fundamental saber apresentar os resultados de forma que faça sentido para as áreas de negócio, que são o gerador primário de todas as demandas.
Podemos portanto adicionar aos skills necessários, por exemplo, o domínio de ferramentas gráficas para apresentação de dados. Mas muito mais importante é a capacidade pessoal de comunicação, tanto para entender (e atender) as necessidades que motivam o projeto, como para apresentar as informações estratégicas que irão orientar as ações de uma empresa. É mais uma disciplina que exige mais experiência profissional do que conhecimento técnico, e está intimamente ligada ao último tópico da nossa lista.

Finalmente chegamos ao coração do trabalho de um cientista de dados. As quatro disciplinas anteriores representam "ferramentas de trabalho", mas esta seção representa o próprio trabalho. A característica fundamental de um cientista de dados é a capacidade de entender e propor soluções para problemas de negócio. Isso exige a identificação das perguntas que devem ser respondidas, bem como de quais são os dados necessários, e como eles devem ser processados para extrair informações estratégicas que tragam as respostas desejadas. Embora não precise (e nem deva) necessariamente ser um especialista em um tipo específico de negócio, ele deve ter experiência e maturidade suficientes para discutir com especialistas de qualquer área, entender os problemas, e identificar os dados e algoritmos mais indicados para resolvê-los.
Ferramentas são importantes, mas não suficientes para que o trabalho seja feito. O cientista de dados é alguém capaz de definir o trabalho a ser feito, as ferramentas mais apropriadas e a forma mais eficiente para executá-lo. É isso que o torna um profissional único, com uma altíssima demanda no mercado atual.
Mas para entender melhor o que tudo isso significa, vamos retornar a um exemplo prático de como data science pode trazer um impacto real numa situação específica.
Voltando à reeleição de Barack Obama, quais foram os fatores determinantes para o sucesso da equipe de data science criada pelo Partido Democrata?
Passo 1: identificar as perguntas a responder. Já listamos os pontos fundamentais que foram atacados nesse caso:
A) Que tipo de ações e eventos deveriam ser feitos para arrecadar fundos, e quais pessoas deveriam ser convidadas para cada um deles.
B) Qual forma de comunicação (e-mail, telefone, visita física, etc) deveria ser usada para convencer cada eleitor a sair de casa no dia da eleição e ir ao local de votação para depositar seu voto.
Os objetivos aqui são bastante claros: arrecadar fundos de campanha e usá-los para converter eleitores.
Passo 2: o que fazer para responder essa perguntas. Ainda de forma bastante simplificada, podemos elaborar um pouco mais esse passo:
A) Unificação das inúmeras bases de dados de eleitores, associando informações relevantes sobre:
i) Quem são os eleitores, incluindo todas as suas características demográficas.
ii) Todos os contatos feitos anteriormente com esses eleitores, e as respectivas respostas.
iii) Todas as manifestações dos eleitores em mídias sociais, incluindo temas e citações a pessoas relacionadas ou não à política.
iv) Cruzamentos dos dados com pesquisas, relacionando demografia e comportamento de eleitores com suas respostas relativas a eleições anteriores (quais são declaradamente Democratas, quais são indecisos, quais votaram ou não em eleições anteriores).
B) Uso de modelos matemáticos para identificação de viabilidade e preferências dos eleitores (relativas aos pontos de interesse listados):
i) Celebridades e temas de interesse que atrairiam cada eleitor a eventos para arrecadar fundos.
ii) Quais eleitores indecisos apresentam maior probabilidade de ser convencidos a votar no candidato Democrata.
iii) Quais os tipos de comunicação aos quais cada eleitor normalmente responde ou não.
C) Uso das informações obtidas para orientar ações concretas - parece óbvio, mas informações estratégicas só fazem diferença quando usadas efetivamente, e isso nem sempre acontece.
Novamente, estamos resumindo um processo extremamente complexo em poucos parágrafos. Mas a essência do que faz o cientista de dados está em traduzir problemas complexos a atividades que levem a soluções tangíveis e objetivas, portanto não estamos tão longe da realidade. E o fato é que, mantendo o foco nos objetivos estabelecidos, a equipe de data science da campanha de Obama foi determinante para reverter o quadro da eleição - o resultado final é conhecido por todos.
Analisando os passos acima, podemos ver que eles envolvem as cinco disciplinas listadas neste artigo. Dificilmente um profissional sem uma sólida formação acadêmica e sem experiência anterior conseguiria definir um projeto como esse e coordenar sua execução.
É importante ressaltar que terminar um doutorado e trabalhar em meia dúzia de projetos não transforma alguém automaticamente num cientista de dados. Cada uma das disciplinas mencionadas exige um aprendizado teórico e prático que só é conquistado ao longo de anos, ou mais provavelmente décadas, de estudo e trabalho. Mesmo o conhecimento teórico sólido de ferramentas, sejam matemáticas ou tecnológicas, não garante que elas sejam aplicadas corretamente na resolução de problemas. E só a experiência real em projetos, preferencialmente de diferentes tipos e áreas de negócio, permite entender os modelos corretos de dados, os algoritmos mais apropriados, e também os recursos necessários para aplicá-los na resolução de cada tipo de problema.
A própria identificação dos problemas a resolver, e seu alinhamento com as reais necessidades de negócio de uma empresa, é provavelmente a parte mais complexa e delicada de qualquer projeto – além de ser a causa mais frequente para o seu possível fracasso! Também é fundamental lembrar que não basta obter os resultados desejados: é preciso saber apresentá-los de forma inteligível para as áreas de negócios que deverão tomar decisões e ações a partir deles.
A complexidade de um projeto de data science torna praticamente mandatória não a contratação de um profissional milagroso, mas a formação de uma equipe, com especialistas sólidos em cada uma das disciplinas, e, idealmente, um cientista de dados com experiência prática para integrar e direcionar essa equipe. É importante lembrar que um projeto complexo exige algumas outras competências mais tradicionais, que não são necessariamente responsabilidade do cientista de dados. Uma recomendação básica é ter na equipe um gerente de projetos experiente, para endereçar as questões típicas: navegar pelos diversos departamentos da empresa, contornar as questões políticas que sempre surgem, conseguir os recursos necessários, controlar prazos, encaminhar a resolução de problemas e ajudar a apresentar os resultados falando a linguagem das áreas de negócio envolvidas.
Para concluir: se você conseguir contratar um cientista de dados com todos os skills aqui mencionados, e além disso capaz de gerenciar equipes, recursos e um projeto como um todo, talvez tenha realmente encontrado um unicórnio. Mas se não conseguir, isso não quer dizer que não possa montar uma excelente equipe e ter sucesso num projeto capaz de impactar positivamente seus negócios.
Luís Flávio Fernandes é empresário e sócio fundador da DirectMind Participações e Consultoria www.directmind.com.br